Cache
- Cache
Redis
WhyRedis
Fast, completely memory-based, implemented in C, uses epoll in the network layer to solve high concurrency issues, single-threaded model avoids unnecessary context switching and race conditions;
| GuavaCache | Tair | EVCache | Aerospike | |
|---|---|---|---|---|
| Category | Local JVM Cache | Distributed caching | Distributed caching | Distributed NoSQL database |
| Application | Local cache | Taobao | Netflix、AWS | Ads |
| Performance | Very high | Higher | High | Higher |
| Persistence | n | y | y | y |
| Cluster | n | Flexible configuration | y | Auto-scaling |
Unlike traditional databases, Redis stores data in memory, so its read and write speeds are very fast. As a result, Redis is widely used for caching purposes and can handle over 100,000 read and write operations per second, making it the fastest known Key-Value database in terms of performance. Additionally, Redis is often used for distributed locking. Beyond that, Redis supports transactions, persistence, Lua scripting, LRU-driven events, and multiple clustering solutions.
1. Simple and Efficient
1) Fully based on memory, with most requests being pure in-memory operations. Data is stored in memory, similar to a HashMap, with both lookup and operation time complexities being O(1);
2)The data structure is simple, and data operations are also simple; the data structures in Redis are specifically designed;
3)It uses a single thread, avoiding unnecessary context switching and race conditions in multi-threading, with no locking and unlocking operations, reducing performance consumption caused by lock contention (multi-threading since version 6.0);
4)It uses the EPOLL multi-path I/O model, non-blocking IO;
5)They use different underlying models, with different underlying implementation methods and application protocols between them and client communication; Redis directly constructs its own VM mechanism because general system calls to system functions would waste a certain amount of time moving and requesting;
2、Memcache
| redis | Memcached |
|---|---|
| In-memory high-speed database | High-performance distributed in-memory cache database |
| Supports hash, list, set, zset, string structures | Only supports key-value structure |
| Places most data in memory | All data is placed in memory |
| Supports persistence, master-slave replication backup | Does not support data persistence and data backup |
| Data loss can be recovered through AOF | After dropping, data cannot be recovered |
| Single-threaded (20,000~40,000 TPS) | Multi-threaded (200,000~400,000 TPS) |
Use cases:
1、If there is a need for persistence or requirements on data types and processing, you should choose Redis. 2、If you need simple key/value storage, you should choose Memcached.
3、Tair
Tair (Taobao Pair) is a distributed Key-Value storage engine developed by Taobao, which can be used as both a cache and a data source (three engines can be switched).
- MDB (Memcache) is an in-memory product that supports kv and hash map-like structures, with the best performance.
- RDB (Redis) supports complex data structures such as List, Set, and Zset, with slightly lower performance, and can provide both caching and persistent storage modes
- LDB (levelDB) is a persistent storage product, supporting kv and hashmap-like structures, with slightly lower performance than the previous two, but offering the highest reliability in persistence
Distributed caching
Storage for large access to small amounts of temporary data (around kb)
Used for caching, reducing access pressure on the backend database
Session scenarios
Applications and computations that require high-speed access to certain data structures (rdb)
Data source storage
Quick data reading (fdb)
Continuous storage and reading of large data volumes (ldb), transaction snapshots
High-frequency update and reading (ldb), inventory
Pain points: In Redis clusters, borrowing cache resources requires specifying the Redis server address. This increases the complexity of program maintenance because Redis servers are likely to be frequently changed. Taobao thought, why can’t it be like operating distributed databases or Hadoop by adding a central node to proxy everything. In Tair, the program only needs to interact with the Tair central node. At the same time, Tair has the concept of a configuration server, which also avoids the need to operate like Hadoop, where each Hadoop node needs an identical configuration file. Changing the configuration file requires the entire cluster to be updated.
4、Guava
Distributed caching provides better consistency, used in cluster environments where multiple nodes use the same cache; there is network I/O, and throughput is greatly related to the size of the cached data;
Local caching is very efficient, but local caching occupies heap memory, which affects garbage collection and system performance.
Design of local caching:
Taking Java as an example, local caching implemented using built-in map or guava is lightweight and fast. Its lifecycle ends with the destruction of the JVM. In multi-instance scenarios, each instance needs to maintain its own copy of the cache, and the cache lacks consistency.
Solving cache expiration:
1、Set the cache expiration time to permanent
2、Distribute the cache invalidation time, don’t set all cache durations to the same value; for example, we can add a random value to the original expiration time, so the repetition rate of expiration times for each cache will be reduced, making it difficult to trigger collective expiration events.
Solving memory overflow:
Step 1, modify the JVM startup parameters to directly increase the memory. (Don’t forget to add the -Xms and -Xmx parameters.)
Step 2, check the error logs to see if there are any other exceptions or errors before the “OutOfMemory” error.
Step 3, review and analyze the code to identify potential locations where memory overflow might occur.
Google Guava Cache
Pain points of locally designed caching:
- Cannot evict data according to certain rules, such as LRU, LFU, FIFO, etc.
- Callback notification when clearing data
- Poor concurrent processing capability, CurrentHashMap can be used for concurrency, but other cache functions need to be implemented manually
- Cache expiration handling, cache data loading and refreshing all need to be implemented manually
Guava Cache scenarios:
- Has very high performance requirements
- Does not change frequently, does not consume much memory
- Requires access to the entire collection
- Data allows for non-real-time consistency
Advantages of Guava Cache:
- Cache expiration and eviction mechanisms
In GuavaCache, you can set the expiration time of keys, including access-based expiration and creation-based expiration. When the cache capacity reaches the specified size, GuavaCache uses LRU (Least Recently Used) to delete infrequently used key-value pairs from the cache
- Concurrency handling capability
GuavaCache is similar to CurrentHashMap and is thread-safe. It provides an API to set concurrency levels, allowing the cache to support concurrent writes and reads. It employs a sharded lock mechanism, which reduces lock contention and enhances concurrency. The sharded lock involves splitting the lock, treating a collection as several partitions, with each partition having its own lock. Updates are locked.
- Prevent cache breakdown
Generally, when querying a key in the cache, if it doesn’t exist, the source data is queried and then refilled into the cache (Cache Aside Pattern). Under high concurrency, this can lead to multiple queries to the source and repeated refilling of the cache, potentially causing the source (DB) to crash or performance to degrade. GuavaCache can control this in the CacheLoader’s load method, allowing only one request to read from the source and refill the cache for the same key, while blocking other requests (similar to integrating the data source, making it convenient for users).
- Monitor cache loading/hit status
Statistics
Issues:
OOM->Set expiration time, use weak references, configure expiration policies
5、EVCache
EVCache is an open-source, fast distributed cache from Netflix that is based on Memcached’s in-memory storage implementation, used to build a large-capacity, high-performance, low-latency, cross-regional, globally available caching data layer.
E:Ephemeral:Data storage is transient, with its own lifespan
V:Volatile:Data can disappear at any time
EVCache is typically suitable for scenarios where strong consistency is not a must
Typical use case: Netflix recommends movies that interest users
EVCache Cluster can process up to200kb requests per second at peak,
The EVCache deployed in the Netflix production system frequently handles over30 million requests per second, storing billions of objects,
across thousands of memcached servers. The entire EVCache clusterhandles nearly 2 trillion requests per day.
The average response latency of the EVCache cluster is approximately 1-5 milliseconds, with a maximum not exceeding 20 milliseconds.
The cache hit rate of the EVCache cluster is around 99%.
Typical deployment
EVCache is linearly scalable, capable of completing expansion within a minute, and achieving load balancing and cache warming within a few minutes.
1、When the cluster starts, EVCache registers each instance with the service registry (Zookeeper, Eureka).
2、When the web application starts, it queries the EVCache server list from the naming service and establishes connections.
3、Clients use the consistency hash algorithm with the key to shard data across the cluster.
6、ETCD
Like Zookeeper, the CP model pursues data consistency, and an increasing number of systems are beginning to use it to store critical data. For example, flash sale systems often use it to store information about each node to control the number of services consuming MQ. Some business systems also use etcd to synchronize configuration data to the nodes of the business system in real time. For instance, the flash sale management backend uses etcd to synchronize the configuration data of flash sale activities to the nodes of the flash sale API service in real time.
Redis underlying
1. redis data types
| Type | Underlying | Application Scenarios | Encoding type |
|---|---|---|---|
| String | SDS array | Posts, comments, hot data, input buffer | RAW « EMBSTR « INT |
| List | QuickList | Comment list, product list, publishing and subscribing, slow queries, monitor | LINKEDLIST « ZIPLIST |
| Set | intSet | Suitable for intersection, union, and set operations, such as friendships | HT « INSET |
| Zset | Skip list | Deduplicated and sorted, suitable for ranking scenarios | SKIPLIST « ZIPLIST |
| Hash | Hash | Structured data, such as stored objects | HT « ZIPLIST |
| Stream | Compact list | Message Queue |
2、Related APIs
| String | SET | SETNX | SETEX | GET | GETSET | INCR | DECR | MSET | MGET |
| Hash | HSET | HSETNX | HGET | HDEL | HLEN | HMSET | HMGET | HKEYS | HGETALL |
| LIST | LPUSH | LPOP | RPUSH | RPOP | LINDEX | LREM | LRANGE | LLEN | RPOPLPUSH |
| ZSET | ZADD | ZREM | ZSCORE | ZCARD | ZRANGE | ZRANK | ZREVRANK | ZREVRANGE | |
| SET | SADD | SREM | SISMEMBER | SCARD | SINTER | SUNION | SDIFF | SPOP | SMEMBERS |
| Transaction | MULTI | EXEC | DISCARD | WATCH | UNWATCH |
3. Redis underlying structure
SDS array structure, used for storing string and integer data and input buffer.
struct sdshdr {
int len; // Records the number of bytes currently used in the buf array
int free; // Records the number of unused bytes remaining in the buf array
char buf[]; // Character array used to store the string
}
Skip List: A partially ordered linked list where some nodes are layered, with each layer being an ordered linked list.
1、Can quickly find the desired node O(logn), with extra storage of double the space
2、Can quickly obtain the head node, tail node, length, and height of the skip list under O(1) time complexity.
Dictionary (dict): Also known as a hash table, it is a data structure used to store key-value pairs.
The entire Redis database is stored using a dictionary (K-V structure) — Hash + array + linked list
Redis dictionary implementation includes: Dictionary (dict), Hash table (dictht), Hash table node (dictEntry).
The dictionary reaches its storage limit (threshold 0.75), requiring rehash (expansion).
-
Initial application requests a default capacity of 4 dictEntry, non-initial application requests double the current hash table capacity.
-
rehashidx=0 indicates that a rehash operation needs to be performed.
3、Newly added data is in the new hash table h[1], while modify, delete, and query operations are performed on the old hash table h[0]
4、Migrating all data from the old hash table h[0] to the new hash table h[1] after recalculating the index values, this process is called rehash.
Progressive rehash
Because the rehashing process can be very slow when the data volume is huge, optimization is necessary. You can batch rehash a portion of the nodes based on the server’s idle time.
ZipList
Ziplists are sequential data structures composed of a series of specially encoded consecutive memory blocks, saving content.
sorted-set and hash elements are few and are small integers or short strings (used directly)
list uses the quicklist data structure for storage, and quicklist is a combination of a doubly linked list and a compressed list. (used indirectly)
Integer sets intSet
An integer set (intset) is a continuous storage structure that stores integers in ascending order.
When the elements of a Redis set type are all integers and fall within the range of 64-bit signed integers (2^64), this structure is used for storage.
Quick list
The quick list (quicklist) is an important data structure in the Redis backend. It is the underlying implementation of Redis 3.2 lists.
(Before Redis 3.2, Redis used doubly linked lists (adlist) and compressed lists (ziplist) for implementation.)
Redis Stream primarily uses listpack (compact list) and Rax tree (radix tree) at the bottom.
listpack represents a serialized string list, listpack can be used to store strings or integers. Used to store the message content of stream.
Rax Tree is an ordered dictionary tree (Radix Tree), arranged according to the lexicographical order of keys, supporting fast location, insertion, and deletion operations.
4、Zset Underlying Implementation
Skip list is a randomized data structure based on parallel linked lists, with simple implementation and insertion, deletion, and search complexities of O(logN). Simply put, a skip list is also a type of linked list, but it adds a jumping function on the basis of linked lists. It is precisely this jumping function that allows skip lists to provide O(logN) time complexity when searching for elements.
Zsetuses ziplist for small data sets to implement, where the sorted set uses adjacent compressed list nodes to store elements, with the first node saving the member and the second saving the score. The collection elements in ziplist are sorted by score from small to large, with smaller scores at the head of the list. For large data sets, it uses a combination of skiplist and hash_map to implement, with time complexity for search, deletion, and insertion being O(logN).
Redis uses skip lists instead of red-black trees because the index structure of skip lists is more serialized and deserialized quickly, making it easier for persistence.
Search
Skiplists store all set elements in order of score from small to large, with an average search time complexity of O(logN), and worst-case O(N).
Insertion
A linked list is selected as the underlying structure to support efficient dynamic addition and deletion. Since the underlying singly linked list of skip lists is ordered, to maintain this order, the list needs to be traversed before insertion to find the insertion point. The time complexity of traversing a singly linked list to find is O(n), and similarly, traversing a skip list also requires traversing the index list, so it is O(logn).
Delete
If the node is still in the index, deletion not only needs to remove the node from the singly linked list but also remove the node from the index; when the singly linked list knows who the deleted node is, the time complexity is O(1), but for the singly linked list, deletion always requires obtaining the predecessor node O(logN) to change the reference relationship in order to delete the target node.
Redis Availability
1、Redis Persistence
Persistence is the process of storing data from memory to local disk to prevent data loss when the server goes down.
Redis provides two persistence mechanisms: RDB (default) and AOF mechanism. Since Redis 4.0, a hybrid persistence is adopted, using AOF to ensure data is not lost as the first choice for data recovery; and using RDB for不同程度的cold backups.
RDB: Stands for Redis Database, a snapshot.
RDB is the default persistence method in Redis. It saves data from memory to the hard disk in the form of snapshots at certain intervals, with the resulting data file named dump.rdb. The snapshot period is defined by the save parameter in the configuration file.
Pros:
1) Only one file dump.rdb for easy persistence;
2) Good disaster recovery capability, one file can be saved to a secure disk.
3)Maximize performance by forking a child process for persistent write operations, allowing the main process to continue handling commands, with only millisecond-level unresponsiveness to requests.
4)Compared to AOF when dealing with large datasets, it has higher startup efficiency.
Cons:
Low data security, as RDB performs persistence at intervals. If a Redis failure occurs between persistence periods, data loss may occur.
AOF: Persistence
AOF persistence (i.e., Append Only File persistence) involves recording every write command executed by Redis into a separate log file. When Redis restarts, it restores data from the persisted log file.
Pros:
1) Data security, AOF persistence can be configured with the appendfsync attribute, which has options like always, where each command operation is recorded in the AOF file once.
2)Writing files in append mode allows for resolution of data consistency issues even if the server crashes mid-process using the redis-check-aof tool.
Disadvantages:
1)AOF files are larger than RDB files and have slower recovery speeds.
2)When dealing with large datasets, they have lower startup efficiency compared to RDB.
2、Redis Transactions
A transaction is a single isolated operation: all commands within a transaction are serialized and executed in order. During execution, a transaction is not interrupted by command requests from other clients. A transaction is an atomic operation: either all commands in a transaction are executed, or none are.
Concept of Redis Transactions
The essence of Redis transactions is a set of commands including MULTI, EXEC, WATCH, etc. Transactions support executing multiple commands at once, with all commands in a transaction being serialized. During transaction execution, commands in the serialization queue are executed in order, and command requests submitted by other clients are not inserted into the transaction execution sequence. In summary: Redis transactions are the execution of a series of commands in a queue in a single, sequential, and exclusive manner.
Redis transactions always have consistency and isolation from ACID, and other features are not supported. When the server is running in AOF persistence mode and the appendfsync option is set to always, transactions also have durability.
The Redis transaction feature is implemented through four primitives: MULTI, EXEC, DISCARD, and WATCH.
Transaction commands:
MULTI: Used to start a transaction, it always returns OK. After executing MULTI, the client can continue to send any number of commands to the server. These commands will not be executed immediately but are placed in a queue. When the EXEC command is called, all commands in the queue are executed.
EXEC: Executes all commands within a transaction block. Returns the return values of all commands within the transaction block in the order they were executed. If the operation is interrupted, it returns nil.
WATCH : It is an optimistic lock that provides check-and-set (CAS) behavior for Redis transactions. It can monitor one or more keys, and once any of them is modified (or deleted), subsequent transactions will not execute, and the monitoring continues until the EXEC command is issued. (Flash sale scenario)
DISCARD: Calling this command allows the client to clear the transaction queue and abandon the execution of the transaction, and the client will exit the transaction state.
UNWATCH : The command can cancel the monitoring of all keys.
3、Redis Expiration Policy
Memory Eviction Policy
1) Global selective key space removal
noeviction : When memory is insufficient to accommodate new write data, new write operations will report errors. (Commonly used in dictionary libraries)
allkeys-lru: Remove the least recently used key in the key space. (Cache frequently used)
allkeys-random: Randomly remove a key in the key space.
2) Selective removal of keys in the key space with expiration times
volatile-lru: Remove the least recently used key in the key space with an expiration time set.
volatile-random: Randomly remove a key in the key space with an expiration time set.
volatile-ttl: In the key space with expiration times set, keys with earlier expiration times are removed first.
Cache invalidation strategy
Timed clearing: Create a specified timer for each key with expiration time set.
Lazy Cleanup: Determines during access, not memory-friendly
Periodic Scan Cleanup: Randomly checks 20 expired dictionaries every 100ms. If more than 25% exist, continue the loop to delete.
4. Redis Read/Write Mode
Cache Aside Bypass Cache
Write requests to update the database after deleting cached data. Read requests do not hit the database, and after the query is completed, the data is written to the cache.


The business side handles all data access details, while utilizing the concept of Lazy computation. After updating the DB, it directly deletes the cache and updates through the DB to ensure the data is based on DB results, which can significantly reduce the probability of data inconsistency between the cache and DB.
If there is no dedicated storage service, and it is a business with high data consistency requirements or a business with complex cache data updates, the Cache Aside pattern is suitable. For example, in the early days of Weibo, many businesses adopted this mode.
// Delayed double deletion to ensure eventual consistency,
// preventing the rare case where an outdated read request after the first deletion
// might update the database.
public void write(String key, Object data) {
redis.delKey(key); // First deletion
db.updateData(data); // Update database
Thread.sleep(1000); // Wait briefly
redis.delKey(key); // Second deletion
}
Ensure absolute consistency under high concurrency by first deleting the cache and then updating the data, which requires using a memory queue for asynchronous serialization. In non-high concurrency scenarios, update the data first and then delete the cache, and the delayed double delete strategy basically meets the requirements.
- First update db then delete redis: If redis deletion fails, issues will occur
- First delete redis then update db: During redis deletion, old data is refilled into redis
- First delete redis then update db, sleep then delete redis: Same as the second point, deleting redis after sleep may cause a crash
- Java internal JVM queue: Not applicable to distributed scenarios and reduces concurrency
Read/Write Though
First check if the data exists in the cache; if it does, return it directly. If it does not exist, the cache component is responsible for synchronously loading the data from the database.
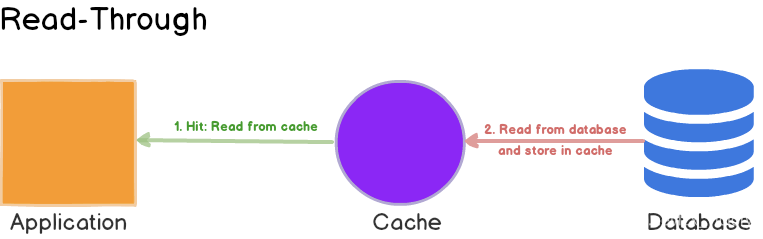
First check if the data to be written already exists in the cache; if it does, update the data in the cache and have the cache component synchronously update it in the database.
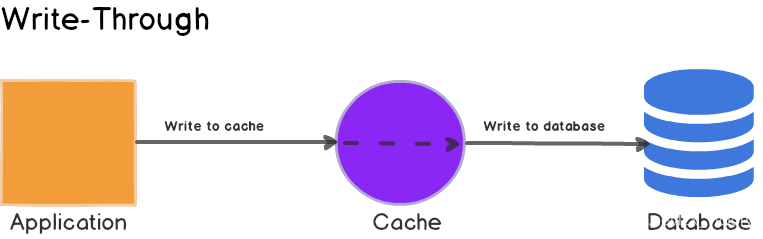
Users perform more read operations. Compared to Cache aside, it is more suitable for cache consistency scenarios. It uses simple shielding to hide lower-level database operations, only operating on the cache.
Scenario:
The Outbox Vector (i.e., the list of a user’s latest Weibo posts) of the Weibo Feed adopts this pattern. For users with fewer and less active followers, after they post a Weibo, the Vector service first queries the Vector Cache. If there is no Outbox record for the user in the cache, the service does not write cache data for that user, updates the DB directly, and then returns. Only if the cache exists will it update via the CAS instruction.
Write Behind Caching (Asynchronous Cache Writing)
For example, for some counting business, a Feed is liked 10,000 times. If you update the DB 10,000 times, the cost is high, while merging it into one request and adding 10,000 directly is a very lightweight operation. However, this model has a significant drawback, that is, data consistency becomes worse, and in some extreme scenarios, data may even be lost.
5、Multi-level caching
Browser local memory cache: Special topic activities, once launched, will not change randomly during the event period.
Browser local disk cache: Logo cache, lazy loading of large images
Server-side local memory cache: Due to the lack of persistence, it will definitely be bypassed upon restart.
Server-side network memory cache: Redis and others. For penetration, it can continue to be layered, and it must ensure that the database is not overwhelmed.
Why not use local server disk for caching?
When the system processes a large number of disk IO operations, since the speed of CPU and memory is much higher than that of disks, it may cause the CPU to spend too much time waiting for disk return processing results. For this part of CPU overhead on IO, we call it iowait.
Seven classic problems of Redis
1、Cache avalanche
It refers to a large-scale failure of cache at the same time, so all subsequent requests will fall back to the database, causing the database to collapse under a large number of requests in a short period.
Solution:
-
Redis High Availability, master-slave + sentinel, Redis cluster, avoid full disk crash
-
Local ehcache cache + hystrix rate limiting & degradation, avoid MySQL being overwhelmed
-
Set cache data expiration time randomly, prevent a large amount of data expiring at the same time.
-
Logically Never Expiring adds correspondingcache tags to every cached data, and updates the data cache when the cache tags expire.
-
Multi-level Caching, when expired, updates the first level through the second level, and is updated by third-party plugins for the second-level cache.
2、Cache penetration
Cache penetration refers to data that is not present in both the cache and the database, causing all requests to fall back to the database, resulting in the database experiencing a large number of requests in a short period and crashing.
Solution:
1)Interface layer adds validation, such as user authentication validation, basic validation for id, and direct interception for id<=0;
2)For data that cannot be fetched from the cache, if it is also not found in the database, you can also write the key-value pair as key-null, and the cache validity period can be set to a shorter duration, such as 30 seconds. This can prevent attacking users from repeatedly using the same id to perform brute-force attacks;
3)Adopt a Bloom filter, which hashes all possible existing data into a sufficiently large bitmap. An data that definitely does not exist will be intercepted by this bitmap, thus avoiding the query pressure on the underlying storage system. (Better to err on the side of caution)
3、Cache breakdown
At this time, due to a large number of concurrent users, reading the cache fails to retrieve data, and simultaneously querying the database, causing the database pressure to increase instantly, resulting in excessive pressure. Unlike cache avalanche, cache breakdown refers to concurrent queries for the same data, while cache avalanche means that different data has expired, and many pieces of data cannot be found, thus querying the database.
Solution:
1)Set hotspot data never expires, process with asynchronous threads.
2)Add write-back operation with mutex lock, return default value quickly on query failure.
3)Cache warming
After the system goes online, directly load relevant expected (e.g., leaderboards) hot data into the cache.
Write a cache refresh page to manually take hot data (e.g., advertising promotions) online and offline.
4、Data inconsistency
When the bandwidth of the cache machine is fully utilized, or there are fluctuations in the data center network, cache updates fail, and new data is not written to the cache, which will lead to data inconsistency between the cache and the database. During cache rehashing, if a cache machine repeatedly behaves abnormally and is taken online and offline multiple times, update requests are repeatedly rehashed. As a result, one piece of data exists on multiple nodes, and each rehash only updates a specific node, leading to some cache nodes producing dirty data.
-
After a cache update fails, it can be retried. Then, the keys that fail to retry are written to the message queue (mq). Once the cache access recovers, these keys are deleted from the cache. When these keys are queried again, they are loaded from the database again, ensuring data consistency.
-
Cache time should be appropriately shortened, allowing cached data to expire earlier and then reload from the DB to ensure eventual data consistency.
-
Instead of using the rehash drift strategy, adopt a cache tiering strategy to minimize the generation of dirty data.
5、Data Concurrency Competition
Data concurrency competition is also common in high-traffic systems, such as ticket systems. If the cache information for a particular train journey expires but there are still many users querying the journey information, or in a microblogging system where a tweet is exactly being evicted from the cache but still has a large number of retweets, comments, and likes, these scenarios will all cause issues with concurrent read access.
- Add write-back operation with mutex lock, return default value quickly on query failure.
- Maintain multiple backups of cache data to reduce the probability of concurrent contention.
6、Hot key issues
Special unexpected events like celebrity marriages, divorces, or affairs, as well as major events or holidays such as the Olympics, Chinese New Year, or online promotional activities like flash sales, double 12, or 618, are all prone to causing hot key situations.
How to identify HotKeys in advance?
- For events that are known in advance, such as important holidays and online promotional activities, it is possible to evaluate potential hot keys in advance.
- For unexpected events that cannot be evaluated in advance, you can perform real-time analysis on corresponding stream tasks through Spark to promptly identify newly published hotspot keys. As for previously issued events that gradually evolve into hot keys, they can be processed through Hadoop’s batch processing tasks for offline computation to identify high-frequency hot keys in recent historical data.
Solution:
-
These n keys are distributed across multiple cache nodes. When a client makes a request, it randomly accesses a hot key with a certain suffix, which helps to distribute the requests for hot keys, preventing any single cache node from being overloaded.
-
The caching cluster can perform master-slave replication and vertical scaling on a single node.
-
Utilize pre-cache within the application, but note that a limit needs to be set.
-
Latency is not sensitive; use scheduled refresh for periodic updates and active refresh for real-time awareness.
-
Like cache penetration, limit escape traffic; perform data backsource and refresh pre-cache per request
-
No matter how it’s designed, a fallback logic must be written, as millions of traffic can come at any moment
7、BigKey problem
For example, in internet systems, there is a need to store a user’s latest 10,000 followers, such as a user’s personal information cache, including basic information, relationship graph counts, and feed statistics. Weibo’s feed content caching is also very common. Generally, a user’s Weibo post is within 140 characters, but many users also post tweets that are 1,000 characters or even longer. These long tweets become big keys
- First, based on the different values in the Redis underlying data structure, the data structure will be reselected
- Can extend new data structures, perform serialization construction, and then write all at once through restore
- Split large keys into multiple keys, set a longer expiration time
Redis partition fault tolerance
1、Redis data partition
Hash: (Unstable)
Client partitioning: Hash + modulo
Node scaling: Changes in data node relationships lead to data migration
Migration amount is related to the number of nodes added: It is recommended to double the capacity
A simple and intuitive idea is to directly use a hash to calculate, taking the modulus of the number of nodes after hashing the key. It can be seen that when the keys are sufficiently distributed, uniformity can be achieved, but once a node joins or leaves, all existing nodes are affected, and stability becomes 无从谈起.
Consistent Hashing: (Unbalanced)
Client-side sharding: Hash + clockwise (optimized modulo)
Node scaling: Only affects neighboring nodes, but still involves data migration
Double Expansion: Ensures minimal migration data and load balancing
Consistent Hashing can effectively address the stability issue by arranging all storage nodes in a circular Hash ring that connects end-to-end. Each key, after calculating the Hash, will find the first group of storage nodes encountered clockwise to store. When a node joins or leaves, it only affects the subsequent nodes clockwise adjacent to it on the Hash ring, receiving or giving data from that node. However, this also introduces the problem of uniformity. Even if storage nodes can be arranged at equal intervals, it will still lead to data unevenness when the number of storage nodes changes.
Codis’s Hash slots
Codis divides all keys into 1024 slots by default. It first performs a crc32 operation on the key sent by the client to calculate the Hash value, then takes the modulus of the Hashed integer with 1024 to get a remainder. This remainder is the slot corresponding to the key.
RedisCluster
Redis-cluster maps all physical nodes to [0-16383] slots. After obtaining the hash value of a key using the crc16 algorithm, it takes the modulus with 16384, basically adopting an approach of average and continuous allocation.
2、Master-slave mode = simple
The biggest advantage of the master-slave mode is simple deployment, requiring at least two nodes to form a master-slave mode, and it can avoid both read and write becoming unavailable through read-write separation. However, once the Master node fails, the master-slave nodes cannot switch automatically, directly resulting in a decrease in SLA. Therefore, the master-slave mode is generally suited for early-stage business development, low concurrency, and low operational costs.
Principle of Master-Slave Replication:
① Send the PSYNC command from the slave server to the master server
② If it’s the first connection, trigger a full replication. At this point, the master node will start a background thread to generate an RDB snapshot file.
③ The master node will send this RDB to the slave node, which will first write it to the local disk and then load it from the local disk into memory
④ The master will write the write commands during this process into the cache, and the slave node real-time synchronizes this data.
⑤ If the connection is disconnected, after automatic reconnection, the master node propagates commands through incremental replication to the slave node for partially missing data.
Disadvantages
All data replication and synchronization of slave nodes are handled by the master node, which causes excessive pressure on the master node. The master-slave-slave structure is used to solve this, and Redis 4.0 introduced psync2 to solve the problem of incremental synchronization after slave restarts.
3、Sentry Mode = Read-Heavy
A Sentinel cluster, composed of one or more Sentinel instances, can monitor one or more master servers and multiple slave servers. Sentry Mode is suitable for business scenarios where read requests far outnumber write requests, such as caching event information in a flash sale system. If there are many write requests, when the number of cluster slave nodes increases, the pressure on the Master node to synchronize data will be very high.
When a master server enters an offline state, Sentinel can promote one of its slave servers to become a new master server to continue providing services, thus ensuring high availability for Redis.
Check subjective offline status
Sentinel sends a PING command to all instances that have established a command connection with it (master servers, slave servers, and other Sentinels) once per second
If an instance returns an invalid response within down-after-milliseconds milliseconds, Sentinel will consider the instance subjectively down (SDown)
Check objective offline status
When a Sentinel determines a master server as subjectively down, Sentinel will send a command to query the host status to all other Sentinels monitoring this master server.
If the number of Sentinel instances that judge the master server as subjectively down reaches the quorum number specified in the Sentinel configuration, then the master server will be determined to be objectively down (ODown).
Election Leader Sentinel
When a master server is judged as objectively down, all Sentinels monitoring this master server will select a Leader Sentinel through an election algorithm (Raft) to perform the failover (故障转移) operation.
Raft algorithm
The Raft protocol is a protocol used to solve consistency problems in distributed systems. The nodes described in the Raft protocol have three states: Leader, Follower, and Candidate. The Raft protocol divides time into individual Terms (terms), which can be considered a form of “logical time.” Election process: ①Raft uses a heartbeat mechanism to trigger Leader elections. After the system starts, all nodes are initialized as Followers with term 0.
② If a node receives a RequestVote or AppendEntries, it will maintain its Follower status.
③ If a node does not receive an AppendEntries message within a certain period and does not discover a Leader within its timeout, the Follower will become a Candidate and begin to campaign for Leader. Once converted to a Candidate, the node immediately starts the following actions: – Increase its own term and start a new timer – Vote for itself, send RequestVote to all other nodes, and wait for their replies.
④ If before the timer times out, the node receives a majority of nodes’ agreement votes, it becomes the Leader. It also sends notifications to other nodes through AppendEntries.
⑤ Each node can only cast one vote within a term, following a first-come, first-served strategy. The Candidate votes for itself, and the Follower votes for the first node that receives a RequestVote.
⑥ The timer in the Raft protocol uses random timeouts (a key factor in elections). The first node to transition to Candidate initiates the vote, thereby obtaining a majority vote.
Selection of the main server
When the Leader Sentinel is elected, the Leader Sentinel will select a new primary server from the servers based on the following rules.
- Filter out nodes that are down in subjective and objective terms
- Select the node with the highest slave-priority configuration, if any, otherwise continue selecting
- Select the node with the largest replication offset, as a larger replication offset indicates more complete data replication
- Choose the node with the smallest run_id, because a smaller run_id indicates fewer restarts
Failover
When the Leader Sentinel completes the selection of a new master server, the Leader Sentinel will perform a failover operation on the decommissioned master server, mainly consisting of three steps:
1、It will promote one of the Slaves of the failed Master to a new Master, and change the other Slaves of the failed Master to replicate the new Master;
2、When a client attempts to connect to a failed Master, the cluster returns the address of a new Master to the client, ensuring that the cluster’s current state has only one Master.
3、After the switch between Master and Slave servers, the contents of the configuration files—redis.conf for the Master, redis.conf for the Slave, and sentinel.conf—will change accordingly. Specifically, the Master’s redis.conf configuration file will include an additional line for replicaof, and the monitored targets in sentinel.conf will be adjusted.
4、Cluster mode = write-heavy
To avoid excessive load on a single node causing instability, the cluster mode employs the consistent hashing algorithm or the hash slot method to distribute keys across various nodes. Each Master node is followed by several Slave nodes, used for failover switching in case of failures. Clients can connect to any Master node, and within the cluster, requests are forwarded to different Master nodes based on different keys.
How does the cluster mode achieve high availability? Nodes within the cluster periodically probe each other to check if they are alive. If a majority of nodes determine that a node has failed, it is removed from the cluster, and one node from the Slave nodes is elected to replace the failed Master node. The entire principle is basically the same as the sentinel mode.
Although the cluster mode avoids the single-node Master problem, synchronizing data within the cluster consumes some bandwidth. Therefore, the cluster mode is only used when there are more write operations, while in most other cases, the sentinel mode can meet the requirements.
5. Distributed Lock
Implementing Redis optimistic locking using Watch
Optimistic locking is based on the CAS (Compare And Swap) concept of comparing and replacing, which does not consume resources due to lock waiting, but requires repeated retries. However, it is also because of the retry mechanism that it can respond quickly. Therefore, we can use Redis to implement optimistic locking (flash sales). The specific approach is as follows:
1. Utilize Redis’s watch feature to monitor the status value of this redisKey. 2. Obtain the value of the redisKey, create a Redis transaction, and increment the value of this key by 1. 3. Execute this transaction; if the value of the key has been modified, roll it back; the key will not be incremented.
Using setnx to prevent overselling of inventory A distributed lock is a way to control synchronized access to shared resources between distributed systems. It serializes shared resources using Redis’s single-threaded特性.
// It is recommended to acquire a lock using the SET command with NX and EX options
String result = jedis.set(lockKey, requestId, "NX", "EX", expireTime);
// Using SETNX alone can be problematic:
// if the thread holding the lock dies, other threads may never be able to acquire the lock
String result = jedis.setnx(lockKey, requestId);
// Releasing a lock like this is NOT atomic and may accidentally release a lock
// that was just acquired by another thread
if (requestId.equals(jedis.get(lockKey))) {
jedis.del(lockKey);
}
// Recommended: use Redis + Lua script to ensure atomicity
String lua = "if redis.call('get', KEYS[1]) == ARGV[1] " +
"then return redis.call('del', KEYS[1]) " +
"else return 0 end";
Object result = jedis.eval(
lua,
Collections.singletonList(lockKey),
Collections.singletonList(requestId)
);
Problems with Distributed Locks:
- Client long-term blocking leading to lock expiration issue
The issue of asynchronously starting another thread within the calculation time to check whether the key has expired. When the lock expiration time is close to expiration and the logic is not yet completed, extend the lock expiration time.
-
Redis server clock drift issue causing concurrent locking. Redis’s expiration time is dependent on the system clock. If the clock drift is too large, theoretically, it is possible to affect the calculation of expiration time.
-
Single-node instance failure, lock not synchronized in time leading to loss
RedLock algorithm
-
Get the current timestamp T0, configure clock drift error T1
-
Acquire all N/2+1 locks one by one in a short period, end time point T2
-
The actual processing duration that the lock can use becomes: TTL - (T2 - T0) - T1
This solution uses multiple nodes to prevent Redis’s single point of failure, but its effectiveness is generally average and it also fails to prevent:
-
Locks being held by two clients simultaneously due to master-slave switching
In most cases, the duration is extremely short, and there are issues when using Redlock to acquire a node lock during a switch. This is already a very low probability time, and it cannot be avoided. Redis distributed locks are suitable for idempotent transactions. If you must ensure security, you should use Zookeeper or a DB, but, performance will drop dramatically.
Compared to Zookeeper distributed locks
- Redis distributed lock actually requires constantly trying to acquire the lock, which is quite performance-intensive.
- Zookeeper distributed locks, you just need to register a listener, no need to continuously actively try to acquire the lock, ZK acquires locks in the order they were locked, so it’s a fair lock, performance is similar to MySQL, and the difference with Redis is significant
Redission production environment distributed locks
Redisson is an open-source distributed lock component based on the Netty framework, which is built on NIO.
However, when the business must ensure strong data consistency, i.e., it is not allowed to repeatedly acquire the lock, such as in financial scenarios (repeated ordering, repeated transfers), please do not use Redis distributed lock. CP model can be used instead, such as: zookeeper and etcd.
| Redis | zookeeper | etcd | |
|---|---|---|---|
| Consistency algorithms | 无 | paxos(ZAB) | raft |
| CAP | AP | CP | CP |
| High Availability | Master-slave cluster | n+1 | n+1 |
| Implementation | setNX | createNode | restfulAPI |
6、redis heartbeat detection
During the command propagation phase, the server will by default send ACK commands to the master server at a frequency of once per second:
1、Check the connection status of master-slave Check the network connection status between the master and slave servers
The lag value should fluctuate between 0 or 1. If it exceeds 1, it indicates a failure in the connection between the master and slave.
2、Assist in implementing min-slaves, Redis can prevent the master server from executing write commands in unsafe conditions through configuration
min-slaves-to-write 3 (min-replicas-to-write 3 )
min-slaves-max-lag 10 (min-replicas-max-lag 10)
The above configuration indicates: If the number of slave servers is less than 3, or if the lag values of all three slave servers are greater than or equal to 10 seconds, the master server will refuse to execute write commands.
3、Detect missing commands, add retransmission mechanism
If due to network issues, the write command propagated from the master server to the slave server is lost in transit, then when the slave server sends the REPLCONF ACK command to the master server, the master server will notice that the current replication offset of the slave server is less than its own replication offset. Then, the master server will find the data missing from the slave server in the replication backlog buffer based on the replication offset submitted by the slave server, and retransmit this data to the slave server.
Redis in Action
1、Redis optimization
Read/Write Methods In simple terms, it’s about not using keys but rather using range, contains and similar methods. For example, when it comes to user fan counts, top influencers can have tens of millions or even hundreds of millions of followers, so fetching the full fan list can only be done partially. Additionally, when determining whether one user is following another, it’s more efficient to check the follow list and return True/False or 0/1.
KV size If the KV size for a single business is too large, it needs to be split into multiple KV entries for caching. When splitting, access frequency should be considered.
number of keys If the data volume is large, try to keep only frequently accessed hot data in the cache as much as possible, and directly access the DB for cold data.
Read/Write Peak If it is less than the 100,000 level, it can be simply split into a separate Cache pool. If it reaches a QPS of 1 million, then a hierarchical processing of the Cache is required. It is possible to use Local-Cache in conjunction with remote cache, and even continue to stack and split pools within the remote cache. (Multi-level Cache)
Hit Rate The hit rate of caching has a significant impact on the performance of the entire service system. For core high-concurrency access business, sufficient capacity needs to be reserved to ensure that the core business cache maintains a high hit rate. For example, the Feed Vector Cache (Hot News) in Weibo has a hit rate of over 99.5% year-round. To continuously maintain the hit rate of caching, the caching system needs to be continuously monitored, and timely fault handling or failover needs to be performed. At the same time, when some cache nodes are abnormal and the hit rate decreases, the failover solution needs to consider whether to adopt a consistent Hash distribution access drift strategy or a multi-layer data backup strategy.
Expiration Strategy
You can set a shorter expiration time to automatically expire cold keys; or you can attach a timestamp to the key while setting a longer expiration time, such as many keys in internal business systems like key_20190801.
Cache Penetration Time The average cache penetration loading time is also important in some business scenarios. For business data that has a long loading time or requires complex calculations after cache penetration, and has a high access volume, more capacity should be configured to maintain a higher hit rate, thereby reducing the probability of penetrating to the DB, to ensure the access performance of the entire system.
Caching Operational Manageability When considering the operational manageability of caching, it is necessary to consider cluster management of the caching system, how to perform one-click scaling and resizing, how to upgrade and modify caching components, how to quickly detect and locate issues, and how to continuously monitor and alert. It is best to have a comprehensive operational platform that integrates various operational tools.
Caching Security Regarding caching security, one approach is to restrict source IPs, allowing only internal network access, while also encrypting and authenticating access.
2. Redis Hot Upgrade
When upgrading the version or fixing bugs in Redis, if a direct restart is performed for the changes, as data recovery is required, this process takes nearly 10 minutes, which is too long and severely affects system availability. To address this issue, the hot upgrade feature of Redis can be extended, allowing upgrade operations to be completed in milliseconds without affecting business access.
The hot upgrade solution is as follows: First, build a Redis shell program that saves all properties of redisServer (including redisDb, client, etc.) as global variables. Then, encapsulate all of Redis’s processing logic code into a dynamic link library (so) file. When Redis starts for the first time, it loads recovery data from disk. During subsequent upgrades, the shell program reloads the new redis-4.so to redis-5.so file via commands, completing the functional upgrade and finishing the Redis version upgrade in milliseconds. Moreover, all client connections remain preserved throughout the process. After the upgrade is successful, the original clients can continue read and write operations, and the entire process is completely transparent to the business.