Message Queue
- Message Queue
- Kafka
- Why kafka
- What Kafka
- How Kafka
- Basic production and consumption process
- Consistency
- Availability
- Interview Question
- Online Issue: rebalance
- The role of ZooKeeper
- The role of Replica copies
- Why is read-write separation not supported?
- How to prevent duplicate consumption
- How to ensure data is not lost
- How to ensure ordered consumption
- [Online] How to solve backlogged consumption
- How to avoid message backlog
- How to design a message queue
- Kafka
Kafka
Why kafka
The role of message queues: asynchronous, peak shaving and valley filling, decoupling
For small and medium-sized companies, with relatively average technical capabilities and not particularly high technical challenges, using RabbitMQ (open source, active community) is a good choice; for large companies, with strong infrastructure R&D capabilities, using RocketMQ (Java secondary development) is a great choice.
If it is in the field of big data for real-time computing, log collection and other scenarios, using Kafka is the industry standard, absolutely no problem, the community is very active, it will definitely not fade away, let alone it is almost the de facto standard in this field all over the world.
RabbitMQ
RabbitMQ was initially used for reliable communication in telecommunications and is one of the few products that support the AMQP protocol.
Advantages:
- Lightweight, fast, easy to deploy and use
- Supports flexible routing configuration. In RabbitMQ, there is an exchange module between producers and queues. According to the configured routing rules, messages sent by producers can be sent to different queues. The routing rules are very flexible and can also be implemented by yourself.
- RabbitMQ’s clients support most programming languages and support the AMQP protocol.
Disadvantages:
- If there are a large number of messages piled up in the queue, performance will drop sharply.
- Processes tens of thousands to hundreds of thousands of messages per second. If the application requires high performance, do not choose RabbitMQ.
- RabbitMQ is developed in Erlang, and the cost of functional expansion and secondary development is very high.
RocketMQ
Drawing inspiration from Kafka’s design and making many improvements, it almost possesses all the features and functions that a message queue should have.
- RocketMQ is mainly used for ordered, transactional, stream computing, message push, log stream processing, binlog distribution, and other scenarios.
- After undergoing multiple Double 11 tests, performance, stability, and reliability are undeniable.
- Java development, reading source code, extension, and secondary development are very convenient.
- A lot of optimization has been done on response delay in the e-commerce field.
- Handling several hundred thousand messages per second while responding in milliseconds. If the application pays close attention to response time, RocketMQ can be used.
- 10 times higher performance than RabbitMQ.
- Supports dead-letter queues, DLX is a very useful feature. It can handle the situation where, in exceptional cases, messages cannot be properly consumed by consumers and are placed in a dead-letter queue, and subsequent analysis programs can analyze the content of this dead-letter queue to understand the exceptional situations encountered at that time, thereby improving and optimizing the system.
Cons:
Integration and compatibility with surrounding systems are not very good.
Kafka
High Availability, almost all related open-source software supports it, meeting most application scenarios, especially in the big data and stream computing fields,
- Kafka is efficient, scalable, and persistent. It supports partitioning, replication, and fault tolerance.
- Extensive design for batch and asynchronous processing, so Kafka can achieve very high performance.
- Processes hundreds of thousands of asynchronous messages per second, and if compression is enabled, it can ultimately reach a level of processing 20 million messages per second.
- However, due to being asynchronous and batch processed, the latency is also high, making it unsuitable for e-commerce scenarios.
What Kafka
- Producer API: Allows applications to publish a stream of records to one or more Kafka topics.
- Consumer API: Allows applications to subscribe to one or more topics and process the record streams generated for them.
- Streams API: Allows applications to act as stream processors, converting input streams into output streams.
Message
Kafka’s data unit is called a message. A message can be seen as a “data row” or a “record” in a database.
Batch
To improve efficiency, messages are batched and written to Kafka. Increasing throughput also increases response time
Topic
Topics are used for categorization, similar to tables in a database,
Partition
Topics can be divided into multiple partitions and distributed across the Kafka cluster for easy scalability
Within a single partition, there is an order, and setting the partition to one ensures global order
Replicas
Each topic is divided into several partitions, and each partition has multiple replicas.
Producer
Producers distribute messages uniformly across all partitions of a topic by default:
- Directly specify the partition for the message
- The partition is determined by hashing the message’s key and taking the modulus.
- Poll the specified partition.
Consumer
Consumers consume messages by distinguishing read messages through offsets. The offset of the last read message for each partition is stored in Zookeeper or Kafka, so if a consumer shuts down or restarts, its reading state is not lost.
ConsumerGroup
ConsumerGroup ensures that each partition can only be used by one consumer to prevent duplicate consumption. If a consumer fails within the group, other consumers in the ConsumerGroup can take over the failed consumer’s work and rebalance the partitions.
Node Broker
Connects producers and consumers, single broker can easily handle thousands of partitions and millions of messages per second.
- broker receives messages from producers, sets offsets for messages, and submits messages to be saved to disk.
- The broker provides services to consumers, responding to requests to read partitions, returning messages that have already been submitted to disk.
Cluster
Each partition has a leader, when a partition is assigned to multiple brokers, partition replication is performed through the leader.
Producer Offset
When messages are written, each partition has an offset, which is the latest and largest offset for each partition.
Consumer Offset
Consumers in different consumer groups can store different offsets for a partition, which do not affect each other.
LogSegment
- A partition is composed of multiple LogSegments,
- A LogSegment consists of
.log .index .timeindex .logis appended sequentially, and the filename is named based on the offset of the first message in the file.Indexallows for quick location during log deletion and data lookup.timeStampis used to find the corresponding offset based on the timestamp
How Kafka
Pros
- High Throughput: Handles tens of millions of messages per second per machine. Even with TB-level message storage, it maintains stable performance.
- Zero-Copy Reduces the copy from kernel space to user space, disk achieves DMA copy of Socket buffer through sendfile
- Sequential Read/Write Fully utilizes the ultra-high performance of disk sequential read/write
- Page Cache mmap, Maps disk files to memory, users can modify disk files by modifying memory.
- High Performance: Supports thousands of clients on a single node and guarantees zero downtime and zero data loss.
- Persistence: Messages are persisted to disk. By persisting data to hard drives and using replication to prevent data loss.
- Distributed System, Easy to Scale. All components are distributed, and machines can be scaled without downtime.
- Reliability - Kafka is distributed, partitioned, replicated, and fault-tolerant.
- Client Status Maintenance: The status of messages being processed is maintained on the Consumer side, and it can automatically balance when failures occur.
Application Scenarios
- Log Collection: Kafka can collect logs from various services and process them through a big data platform;
- Message System: Decoupling producers and consumers, caching messages, etc.;
- User Activity Tracking: Kafka is often used to record various activities of web or app users, such as browsing web pages, searching, clicking, etc. This activity information is published by various servers to Kafka Topics, and consumers then subscribe to these Topics to perform real-time monitoring and analysis of operational data, which can also be saved to a database;
Basic production and consumption process
-
When the Producer is created, it creates a Sender thread and sets it as a daemon thread.
-
The produced messages first pass through the interceptor -> serializer -> partitioner, and then the messages are cached in the buffer.
-
The condition for batch sending is: the buffer data size reaches batch.size or linger.ms reaches its upper limit.
-
After batch sending, it is sent to the specified partition, and then written to the broker.
-
acks=0 means that as soon as the message is placed in the buffer, it is considered to have been sent.
-
acks=1 indicates that the message only needs to be written to the primary partition. In this case, if the primary partition crashes after receiving the message confirmation, and the replica partitions haven’t had time to synchronize the message, then the message is lost.
-
acks=all (default)the leader partition will wait** for confirmation from all ISR replica partitions**. This process ensures that as long as at least one ISR replica partition is alive, the message will not be lost.
-
-
If the producer is configured with a retries parameter greater than 0 and confirmation is not received, then the client will retry the message.
-
Successfully replicated to the broker, returning production metadata to the producer.
Leader election
-
Kafka maintains a collection called ISR (in-sync replica) for each Topic on Zookeeper
-
Only when all replicas in the collection have synchronized with the replica in the Leader does Kafka consider the message committed
-
Only those Followers that stay synchronized with the Leader should be selected as the new Leader
-
Assuming a topic has N+1 replicas, Kafka can tolerate up to N servers being unavailable, with low redundancy
If all replicas in the ISR are lost, then:
- You can wait for any replica in the ISR to recover, and then serve external requests, which requires waiting time
- Select a replica from the OSR to be the Leader replica, which will result in data loss
Replica message synchronization
First, the Follower sends a FETCH request to the Leader. Then, the Leader reads the message data from the underlying log file and updates the LEO value of the Follower replica in its memory to the fetchOffset value in the FETCH request. Finally, it attempts to update the partition high watermark value. After the Follower receives the FETCH response, it writes the message to the underlying log and then updates the LEO and HW values.
Related Concepts: LEO and HW.
- LEO: Stands for log end offset, which records the offset value of the next message in the replica’s log. If LEO=10, it means the replica has stored 10 messages, with offset values ranging from [0, 9].
- HW: The HW value (high watermark) refers to the backed-up offset. For the same replica object, its HW value will not exceed its LEO value. All messages with values less than or equal to HW are considered “backed up” (replicated).
Rebalance
- Number of team members changes
- Number of subscribed topics changes
- Number of partitions of subscribed topics changes
After the leader election is completed, when any of the three situations occur, the leader starts allocating the consumption plan based on the configured RangeAssignor, i.e., which consumer is responsible for consuming which topics’ partitions. Once the allocation is complete, the leader will encapsulate this plan into a SyncGroup request and send it to the coordinator. Non-leaders will also send SyncGroup requests, but their content will be empty. After receiving the allocation plan, the coordinator will package the plan into the SyncGroup response and send it to each consumer. This way, all members of the group will know which partitions they should consume.
Partition allocation algorithm RangeAssignor
-
The principle is to perform an integer division based on the total number of consumers and the total number of partitions to evenly distribute them among all consumers.
-
Consumers subscribing to a Topic are sorted by name in lexicographical order, evenly distributed, and the remaining ones are assigned from the front to the back in lexicographical order.
Create, Read, Update, Delete
kafka-topics.sh --zookeeper localhost:2181/myKafka --create --topic topic_x
--partitions 1 --replication-factor 1
kafka-topics.sh --zookeeper localhost:2181/myKafka --delete --topic topic_x
kafka-topics.sh --zookeeper localhost:2181/myKafka --alter --topic topic_x
--config max.message.bytes=1048576
kafka-topics.sh --zookeeper localhost:2181/myKafka --describe --topic topic_x
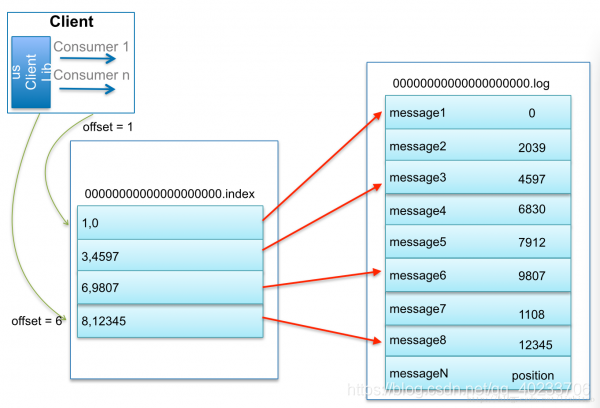
How to view a message with an offset of 23?
By querying the skip list ConcurrentSkipListMap, it locates to 00000000000000000000.index. Using binary search in the offset index file, it finds the largest index entry not greater than 23, i.e., the offset 20 column, and then sequentially searches for the message with offset 23 starting from the physical location 320 in the log segment file.
Splitting file
- Size Segmentation The size of the current log segment file exceeds the value configured by the broker-side parameter
log.segment.bytes - Time Segmentation The difference between the maximum timestamp of messages in the current log segment and the system timestamp is greater than the value configured by
log.roll.ms - Index Segmentation The size of the offset or timestamp index file reaches the value configured by
log.index.size.max.byteson the broker side - Offset Segmentation The difference between the offset of appended messages and the offset of the current log segment is greater than Integer.MAX_VALUE
Consistency
Idempotency
Ensure that consumers do not process messages repeatedly when they are resent. Even if consumers receive duplicate messages and process them repeatedly, it must
still be guaranteed that the final result is consistent. The concept of idempotency in mathematics is: f(f(x)) = f(x)
How to implement?
Add a unique ID, similar to a database primary key, to uniquely identify a message.
ProducerID – Assigned a unique PID each time a new producer is initialized.
SequenceNumber – For each PID and each topic it sends data to, there is a monotonically increasing SN (starting from 0).

How to elect
- Use Zookeeper’s distributed lock election controller and notify the controller when nodes join or leave the cluster.
- The controller is responsible for conducting partition Leader elections when nodes join or leave the cluster.
- The controller uses epoch
ignores small epochsto avoid split-brain: two nodes simultaneously believe they are the current controller.
Availability
- When creating a Topic, you can specify –replication-factor 3, which means no more than the number of replicas for the broker.
- Only the Leader is responsible for read and write operations, while Followers periodically pull data from the Leader.
- ISR is a list of replicas maintained by the Leader that are kept in sync, i.e., the list of currently active replicas. If a Follower falls too far behind, the Leader will remove it from the ISR. During elections, Followers are prioritized from the ISR.
- Set acks=all. The Leader only sends an ACK to the Producer after receiving ACKs from all Replicas in the ISR.
Interview Question
Online Issue: rebalance
Due to the rebalancing within the consumer group caused by changes in the cluster architecture, if the Kafka cluster has a large number of nodes, such as hundreds, the rebalancing may take a long time, lasting from minutes to hours. During this time, Kafka is essentially in an unusable state, greatly affecting its TPS.
Cause:
-
Number of team members changes
-
Number of subscribed topics changes
-
Number of partitions of subscribed topics changes
Member crash and member 主动 leaving are two different scenarios. Because when a member crashes, it does not actively inform the coordinator of this event, and the coordinator may need an entire session.timeout period (heartbeat period) to detect such a crash, which inevitably causes consumer lag. It can be said that leaving the group is an active initiation of rebalance; while a crash is a passive initiation of rebalance.

Solution:
加大超时时间 session.timout.ms=6s
加大心跳频率 heartbeat.interval.ms=2s
增长推送间隔 max.poll.interval.ms=t+1 minutes
In recent years, the interview questions I’ve memorized to get into Alibaba
The role of ZooKeeper
Currently, Kafka uses ZooKeeper to store cluster metadata, member management, Controller elections, and other administrative tasks. After the completion of the KIP-500 proposal, Kafka will no longer rely on ZooKeeper at all.
- Storing metadata refers to all data of topic partitions being stored in ZooKeeper, and other “people” need to stay aligned with it.
- Member management refers to the registration, deprecation, and attribute changes of Broker nodes.
- Controller election refers to the election of the cluster Controller, including but not limited to topic deletion, parameter configuration, etc.
In a nutshell: KIP-500, which uses the community-developed Raft-based consensus algorithm, achieves Controller self-election.
Similarly for metadata storage, the popularity of etcd based on Raft algorithm has been increasing in recent years.
More and more systems are starting to use it to store critical data. For example, flash sale systems often use it to store node information to control the number of MQ service instances. There are also configuration data of business systems, which are synchronized to the nodes of the business systems in real-time via etcd. For instance, the flash sale management backend uses etcd to synchronize the configuration data of flash sale activities to the nodes of the flash sale API services in real-time.
The role of Replica copies
Kafka can only provide read-write services to external clients through the Leader replica, responding to requests from the Client side. Follower replicas only adopt a pull (PULL) method, passively synchronizing data from the Leader replica, and are ready to step in as the Leader replica at any time after the Broker hosting the Leader replica goes down.
- Starting from Kafka 2.4 version, the community can allow Follower replicas to provide read services to a limited extent through configuration parameters.
- The main method to ensure consistency previously was the high watermark mechanism, but the high watermark value could not guarantee data consistency in scenarios with continuous leader changes. Therefore, the community introduced the Leader Epoch mechanism to address the shortcomings of the high watermark value.
Why is read-write separation not supported?
-
Since Kafka 2.4, Kafka has provided limited read-write separation.
-
Not applicable to scenarios. Read-write separation is suitable for scenarios where read load is high, while write operations are relatively infrequent.
-
Synchronization mechanism. Kafka implements follower synchronization using the PULL method, and the replication delay is relatively large.
How to prevent duplicate consumption
- Code level, each consumption needs to submit offset
- Through MySQL’s unique key constraint, combined with Redis to check if the id has been consumed, storing in Redis can directly use the set method
- In cases of large volume and allowing for false positives, using a Bloom filter can also work
How to ensure data is not lost
- Producer producing messages can solve the issue by configuring ack=all in comfirm
- Broker synchronization process where the leader crashes can be resolved by configuring ISR replica + retry
- Consumer loss can be addressed by disabling the auto-commit offset feature, and submitting the offset when the system processing is complete
How to ensure ordered consumption
- Single topic, single partition, single consumer, single-threaded consumption, low throughput, not recommended
- If you just need to ensure order for a single key, request a separate memory queue for each key, and have each thread consume a separate memory queue. This will ensure the order for a single key (e.g., user ID, event ID).
[Online] How to solve backlogged consumption
- Fix the consumer to make it capable of consuming and expand to N machines
- Write a distribution program to evenly distribute the Topic to temporary Topics
- Simultaneously start N consumer instances, consuming different temporary Topics
How to avoid message backlog
- Increase consumer parallelism
- Batch consumption
- Reduce the interaction times of component IO
- Priority consumption
if (maxOffset - curOffset > 100000) {
// TODO Priority handling logic for message backlog situations
// Unprocessed messages can be either discarded or logged
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
// TODO Normal message consumption process
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
// How to design a message queue
How to design a message queue
Need to support rapid horizontal scaling, broker+partition, placing partitions on different machines, migrating data based on topics when adding machines, distributed systems need to consider consistency, availability, and partition tolerance
- Consistency: Producer message acknowledgment, consumer idempotency, Broker data synchronization
- Availability: How to ensure data is not lost or duplicated, data persistence methods, how to read and write during persistence
- Partition Tolerance: What election mechanism to adopt, how to perform multi-copy synchronization
- Massive Data: How to Solve Message Backlog and Performance Degradation of massive Topic
In terms of performance, it can draw inspiration from time wheel, zero copy, IO multiplexing, sequential read/write, and compressed batch processing